Introduction
In particular, Algeria is one among many other countries around the world where people suffer from cancer, according to the National Registry Network of Cancer. The number of new cases in 2015 was 42,720, and it is estimated to reach 61,031 by 2025. Cancer diagnosis using traditional methods has resulted in moderate outcomes due to uncertainties in diagnostic precision, as cancer itself falls under precision medicine, belonging to the class of complex systems that are difficult to account for. This complexity consequently contributes to inaccurate diagnoses. On the other hand, beyond diagnostic precision, although fundamental clinical observations have been combined with the TNM staging approach, the results always reflect erroneous predictions of diagnoses. These imprecise results are, among other factors, due to the limited ability of humans to integrate and process large amounts of sample data. Moreover, the literature confirms that traditional analysis methods such as statistical analysis and multivariate analysis are less accurate than AI tools. To address this issue, the field of oncology has benefited from Artificial Intelligence through Data Science. A more specific concept, namely Machine Learning, a subfield of AI, enables the use of a wide variety of models to improve not only the accuracy of cancer susceptibility, diagnosis, and survivability predictions, but also the training of these ML models. However, the question arises:
-
Are these models sufficiently discriminating to diagnose a particular type of cancer, such as neuroendocrine tumors?
-
Are the relevant probabilities of cancer prediction sufficiently precise?
The first section of this paper serves as an introduction, while the second section provides background information on the main phases of a cancer patient’s lifecycle. The third section discusses related work on cancer susceptibility, diagnosis, and survivability predictions. The fourth section presents in detail a machine-learning model structure that addresses specific key phases in the cancer patient lifecycle. The fifth section of this paper examines the strengths and weaknesses of these models. The final section concludes the paper.
1. Background
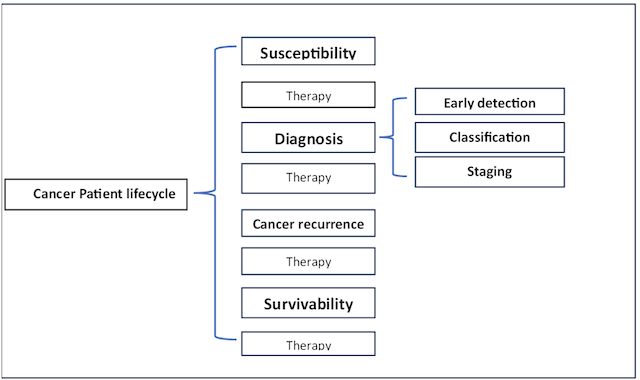
In the context of the cancer patient lifecycle, several key concepts play pivotal roles. These concepts encompass the evaluation of an individual’s susceptibility to cancer, the crucial process of diagnosis, which involves early detection, classification of cancer types, and staging, and the assessment of survivability, which quantifies a patient’s ability to endure the challenges posed by cancer (3,4).
-
Susceptibility is the first step in the cancer patient lifecycle which estimates or predicts the risk of developing cancer in the future.
-
Diagnosis is the second step in the cancer patient lifecycle that enables one to decide whether or not one is a cancer-affected patient, and this step is composed of three sub phases:
-
The early detection of the cancer It consists of detecting the cancer in the very beginning stages.
-
Classification is the process of distinguishing between the related cancer subtypes and detecting benign versus malignant tissue.
-
Staging determines how aggressive and advanced the cancer is.
-
Survivability It is the process of quantifying the ability of a cancer patient to live for a well-defined period such that he is suffering from cancerous conditions.
2. State of the art
Various research and works in AI have been proposed to address the cancer patient’s lifecycle. Table 1 shows some of these works, with the cancer patient lifecycle mainly consisting of three key phases: susceptibility, diagnosis, and survivability.
2.1 Susceptibility
Several studies, such as Mohan Kumar et al. [6], have demonstrated that using decision trees, support vector machines, and logistic regression to predict cervical cancer resulted in high classification performance, with SVM showing the highest accuracy among other algorithms. El Guabassi et al. [5] applied six machine learning algorithms, including Neural Networks (ANN), Naive Bayes (NBs), K-nearest neighbors (KNN), Support Vector Machine (SVM), Decision Trees (DTs), and logistic regression, for predicting and diagnosing lung cancer. SVM achieved the highest accuracy rate of 94.6%. Bharat et al. [7] conducted a study utilizing KNN, Naive Bayes, Cart, and Support Vector Machine, with the results indicating that Support Vector Machine is the most suitable technique for prediction.
2.2 Diagnosis
In [9], authors developed an ML-based model to identify factors associated with Neuroendocrine tumors (NET) and factors impacting time to NET diagnosis using logistic regression and conditional inference trees. The discrimination of the two classifiers was greater than 0.8, although the precision was less than 0.70. Surgey K. et al. [10] proposed a pipeline ML-based model to predict metastasis risk for Pancreatic Neuroendocrine Tumors and identify different types of tissues in Whole Slide Images (WSI). They utilized ML algorithms Convolutional Neural Network and an assembling approach, with high concordance between the model findings and pathologists’ annotations. Additionally, the F-1 score was greater than 0.70%, with decision trees in the assembling approach identified as the best classifier among others. A published study by A. Rovcanin et al. [12] describes the application of Artificial Intelligence for the diagnosis and therapy of prostate cancer, using ANN as the only classification algorithm with four parameters. They indicated that ANN is one of the best algorithms for diagnosing or treating prostate cancer.
2.3 Survivability
In [14], the authors proposed an ML-based model to predict the recurrence and survivability of colorectal cancer patients. They utilized ML algorithms such as Logistic Regression (LR), Naive Bayes (NB), C5.0, Random Forest (RF), Support Vector Machine (SVM), and Artificial Neural Network (ANN), where the results demonstrated that ANN achieved the highest ROC/AUC score at 87%. Xiaoyun Cheng et al. [13] published a study predicting the survival rate of patients with rectal neuroendocrine tumors, in which they employed ML algorithms such as C-SVC and NU-SVC (Support Vector Classification), Random Forest (RF), AdaBoost, and Extreme Gradient Boosting (XG Boost). The predictive model using the XG Boost algorithm exhibited the best predictive performance with an AUC of 0.87. Byeonggwan Noh et al. [16] investigated the survival rate of liver cancer patients in two groups, one diagnosed histologically and the other through imaging or radiology. The ML algorithms used were voting ensembles, Logistic Regression, K Nearest Neighbors, Decision Tree, Support Vector Machine, Random Forest, Extreme Gradient Boosting Tree, Light GBM, and Natural Gradient Boosting. The results showed that the XG Boost algorithm had the best predictive performance.
3. Cancer Patient Lifecycle
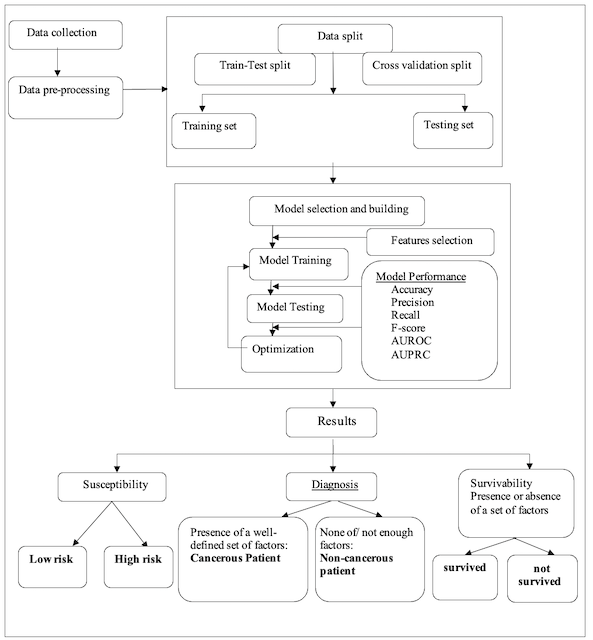
At this level, we consider the three primary phases in the cancer patient lifecycle: susceptibility, diagnosis, and survivability (see Fig.1), where each of them can be modeled using ML techniques. Firstly, the flowcharts of these cancer phases share a common part (see Fig.2), which starts with a data collection step consisting of gathering patient data and forming the dataset used to accomplish the predictive task of the ML model. This data collection step is followed by a data preparation process, in which the data typically undergo well-known techniques: data cleaning, data integration, data reduction, and data transformation. Once the data have been preprocessed, it is time to split the entire dataset into a training set for ML classifiers and a testing set to evaluate the generalization ability of the model. This data split step can be performed using either Train and Test Split or Cross-Validation methods. Then, it is the ML’s turn to build and optimize the model iteratively using various ML algorithms and likely a set of performance metrics to evaluate the predictive capability of such an ML model.
Table 1. Related work for susceptibility, diagnosis, and survivability steps using ML.
|
Cancer Step |
Reference |
ML- algorithms |
The best classifier |
Performance metrics |
|
Susceptibility |
[6] |
decision tree, support vector machine, and logistic regression. |
SVM, accuracy rate: 98% |
accuracy |
|
[5] |
Neural Networks (ANN), Naive Bayes (NBs), K nearest neighbors (KNN), support vector Machine (SVM), Decision Trees (DTs) and logistic regression. |
SVM, accuracy rate: 94,6% |
accuracy |
|
|
[7] |
KNN, Naive Bayes, Cart, and SVM. |
SVM, accuracy rate: 99% |
accuracy |
|
|
Diagnosis |
[9] |
logistic regression and conditional inference tree |
Greater than 0.8 |
Discrimination and precision |
|
[10] |
Convolutional neural network, ensemble approach |
Not mentioned |
Sensitivity, specificity, F1 score, accuracy. |
|
|
[12] |
ANN |
ANN, accuracy rate: 92.7% |
confusion matrix, specificity, sensibility, accuracy. |
|
|
Survivability |
[14] |
Logistic Regression (LR), Naive Bayes (NB), C5.0, Random Forest (RF), SVM and ANN |
ANN scores of 0.87 |
AU-ROC |
|
[13] |
C-SVC and NU-SVC(support Vector Classification), RF, AdaBoost and extreme Gradient Boosting (XG Boost), and Naive Bayes (NB) |
XG Boost AUC of 0.87 |
ROC/AUC |
|
|
[16] |
voting ensembles, LR, KNN, Decision Tree, SVM, RF, Extreme Gradient Boosting Tree, Light GBM, Natural Gradient Boosting |
XG Boost, all the indicators greater than 70 |
Accuracy, precision, recall score, F1-score |
Figure 1. Cancer patient Lifecycle
3.1 Susceptibility
In practical terms, an ML model is used to predict the risk of cancer based on a given set of symptoms, with the outcome being a classification problem output [6,5,7]. This outcome may have exactly two possible values: either a high risk of developing cancer in the future or a low risk (see Fig. 2). It is also possible to address the risk stratification problem by considering the predictive model outcome as a probability reflecting whether or not the associated case has a high risk of developing cancer.
3.2 Diagnosis
To diagnose cancer using machine learning tools, it is sufficient to check for the presence of well-known factors [9] among the selected feature values (see Fig. 2), as these factors somehow influence the model output. With ML-based models, if an instance of the dataset exhibits all or most of these factors, it is then possible to conclude that the associated person has cancerous conditions and is a cancer-affected patient [9,12]. The same approach can be employed to predict the subtypes of cancer or define its staging [10].
3.3 Survivability
The survival status of a cancer patient can be predicted using an ML model, with the outcome being a categorical variable whose value depends on a well-defined set of independent features over a given period [13,14,16]. The model outcome reflects how variations in these features influence the patient’s survival status. Thus, the associated patient either survives for a defined period (see Fig. 2) or presents a non-surviving case for this period.
Figure 2. System Architecture
4. Discussion
4.1 Susceptibility
The first model predicts the risk of cervical cancer using a dataset collected from the UCI repository. The second model’s objective is to diagnose and predict lung cancer early, with the dataset obtained from an online lung cancer prediction system website. The third model diagnoses breast cancer and predicts its risk, with the dataset obtained from the UCI machine learning repository. All the models considered ended up using Support Vector Machine as the best classifier among others to predict the risk stratification for different types of cancer. This classification method involves separating the data points (instances) belonging to different classes using a hyperplane in an N-dimensional space, where N is the number of features [17]. However, the majority of these susceptibility models are based solely on one indicator, which is accuracy, neglecting other performance metrics that can be used to assess the predictive capability of such classifiers. This aspect may represent a weakness for these predictive models.
4.2 Diagnosis
The first model is designed to diagnose neuroendocrine tumors, with the study variables for this retrospective cohort study derived from administrative medical and pharmacy claims data. The second model predicts the risk of metastasis in pancreatic neuroendocrine tumors using deep learning image analysis, with tissue samples obtained from surgical resection of Pan NET patients treated at Emory University Hospital. The dataset for the third model consisted of 200 healthy volunteers and 800 sick volunteers, with the latter examined to measure relevant parameters to establish the presence of cancerous or benign prostate tissue. The discrimination of the first diagnosis model was greater than 0.8. However, compared to the third model, this indicator is very low. The ML algorithms used for this model were logistic regression and decision tree inference only, while the authors of the third ML model used only Artificial Neural Networks [18] as a classification algorithm. In contrast, in the second model, a variety of algorithms have been employed, including the ensemble approach [19].
4.3 Survivability
For the first model, many private and public hospitals were used as study sites. The second model predicts the survival of patients with rectal neuroendocrine tumors, with patient data extracted from the SEER (Surveillance, Epidemiology, and End Results) database. The third model aims to predict the survival rate of liver cancer in Korea, with data provided by the Korean Liver Cancer Study Group and Korea Central Cancer Registry. Although the classification performance of the first and second models was greater than 80% using AU-ROC and ROC/AUC, respectively, it should be noted that assessing an ML model’s performance requires the use of a variety of performance metrics that can be compared with one another to obtain a precise result. However, all performance indicators of the third model were greater than 70%. Nonetheless, the results of this predictive model are considered moderate compared to the first and second models.
Conclusion
In conclusion, this study has introduced machine learning models designed to address distinct phases of the cancer patient lifecycle, namely susceptibility, diagnosis, and survivability. Our evaluation has primarily focused on precision and classification ability. To enhance future research in this field, it is advisable to incorporate a multifaceted array of metrics to improve the accuracy of susceptibility predictions and to explore integrating diverse machine learning algorithms to enhance the performance of the diagnostic model. It is essential to emphasize the importance of meticulous assessments of discriminative capability and precision to ensure the reliability of these models for survivability prediction. Ongoing efforts should be directed toward comprehensive refinements and enhancements in future research endeavors.